统计基础 1
统计研究方法入门
建构
建构(Constructs,即抽象概念):建构是任何难以衡量的东西,因为它可以用许多不同的方式来定义和衡量。
操作定义(Operational Definition):建构的操作定义是我们用于度量建构的单位。 一旦我们在操作上定义了一些东西,它就不再是一个建构。
例:容量是一个建构。我们知道容量是某物占据的空间,但我们还没有定义如何度量这个空间(即升、加仑等)。当我们要用升来度量容量的时候,它不再是一个建构,而是操作定义。
例:分钟已被操作定义了,我们正在测量的东西没有含糊之处。
总体与样本
总体(Population):一个群体中的所有个体。
样本(Sample):一个群体中的部分个体。
参数(Parameter)与统计值(Statistic):参数定义总体的特征,统计值定义样本的特征。
例:总体的平均值用符号 $\mu$ 定义,样本的平均值用 $\bar x$ 定义。
实验
治疗组(Treatment Group):接受不同程度自变量的研究小组,这些小组被用来衡量治疗的效果。
对照组(Control Group):一个没有得到任何治疗的研究小组。这个组被用作比较治疗组的基线。
安慰剂(Placebo):给对照组的受试者一些东西,让他们认为他们正在接受治疗,而实际上他们正在得到一些对他们没有任何影响的东西。(例如糖丸)
盲法(Blinding):盲法是一种用来减少偏见的技术。双盲法可确保执行治疗和接受治疗的患者不知道接受哪种治疗。
数据可视化
频率
频率(Frequency):数据集的频率是某个结果发生的次数。
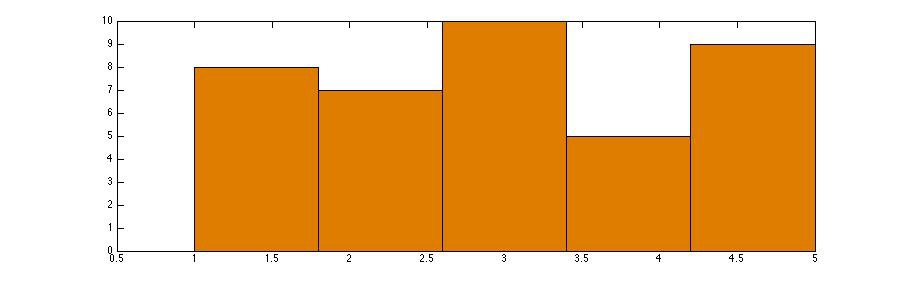
这个直方图显示从 0-5 学生测试的分数。我们看到没有学生得 0 分,8 名学生得 1 分。这些数字就是学生成绩的频率。
比例(Proportion):比例是计数除以总样本的分数。比例可以通过乘以 100 来变成百分数。
例:使用上面的直方图,我们可以看出得 1 分学生的比例为 $\frac{8}{39} \approx 0.2051$ 或 $20.51\%$
直方图
直方图(Histogram):直方图是数据分布的图形表示,组距决定箱子宽度。
调整直方图的组距(bin size)大小将压缩(或展开)分布。
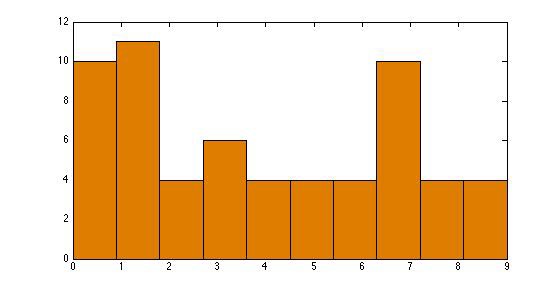
组距为 1
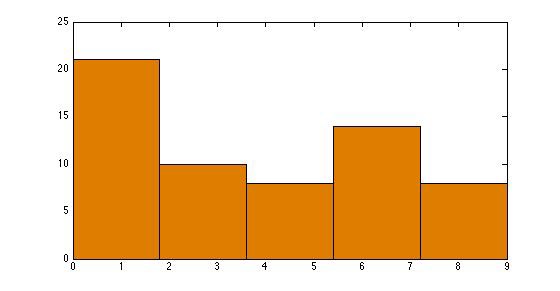
组距为 2
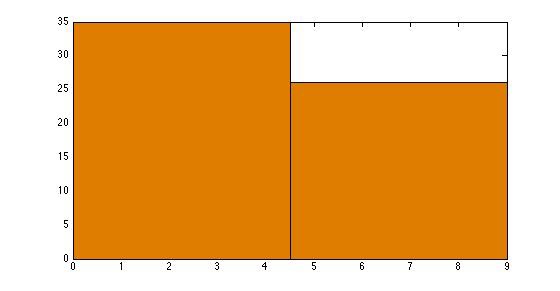
组距为 5
偏斜分布(Skewed Distribution)
正偏斜(Positive Skew):异常值出现在分布的最右端
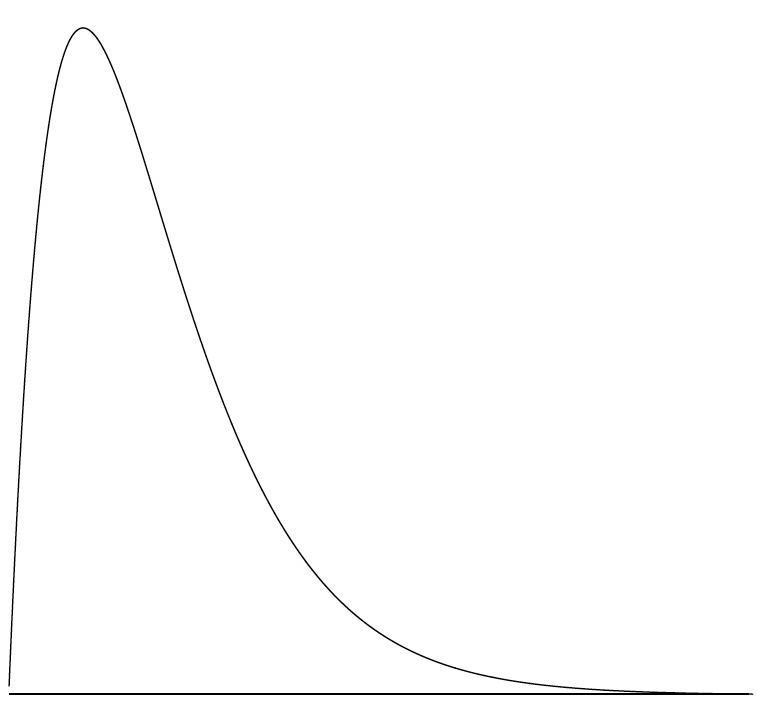
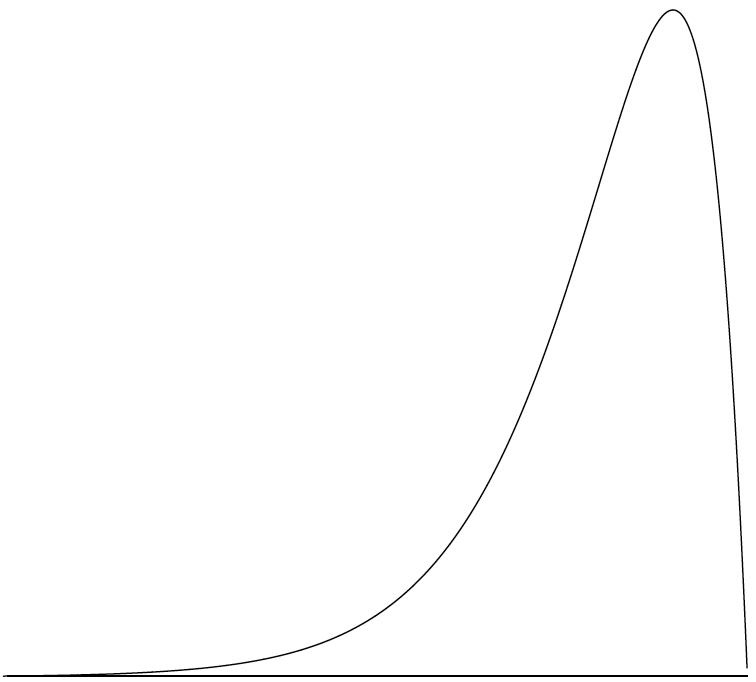
负偏斜(Negative Skew):异常值出现在分布的最左端
集中趋势
均值、中位数和众数
均值(Mean):数据集的均值是数值的平均值,可以通过将所有数据点之和除以数据点数来计算:$$\bar x = \frac{\Sigma^{n}_{i = 0}x_i}{n}$$
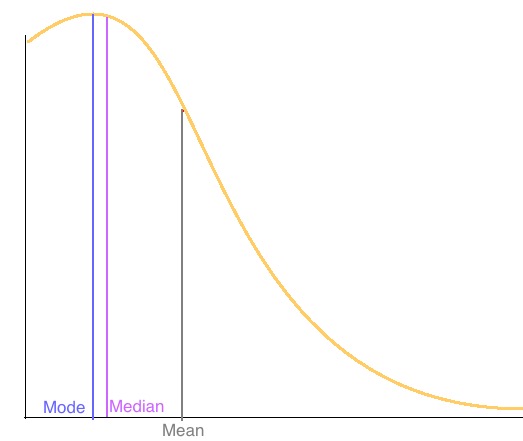
均值受到异常值的影响严重,因此我们说均值不是一个稳健的度量。
中位数(Median):数据集的中位数是直接位于数据集中间的数据点。如果有两个数字在中间,那么中位数就是这两者的平均数。
- 数据集有奇数个数据,$n / 2$ 为数据集中中位数的位置
- 数据集有偶数个数据,$\frac{x_k + x_{k + 1}}{n}$ 给出中间两个数据点的均值
中位数对于异常值是稳健的,因此异常值不会影响中位数的值。
众数(Mode):数据集的众数是数据集中出现频率最高的数据点。
众数对异常值也稳健。
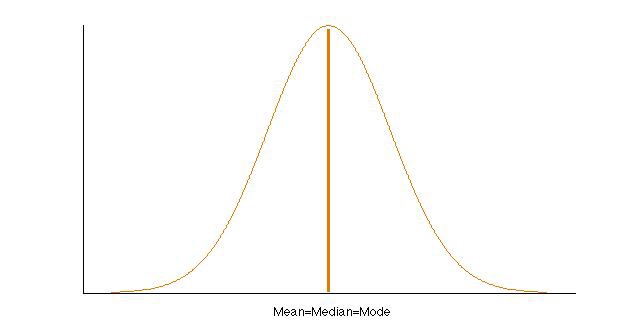
正态分布中,均值 = 中位数 = 众数
差异性
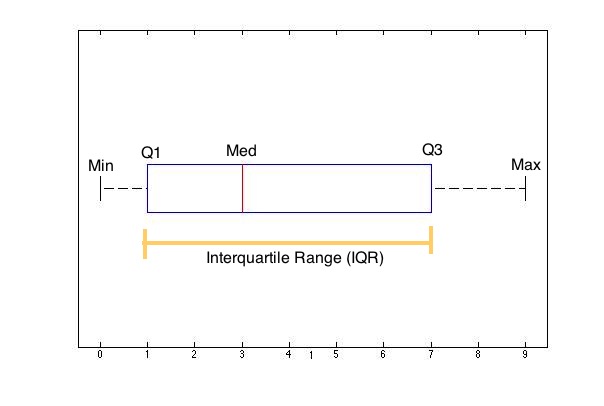
箱形图与 IQR
箱形图(boxplot)是以一种视觉上吸引人的方式展示数据集的 5 个摘要值的方法。 这 5 个值包括最小值、第一四分位数、中位数、第三四分位数和最大值
四分位间距(Interquartile range):四分位间距(IQR)是第一个四分位数与第三个四分位数之间的距离,它给出了我们数据中间 $50\%$ 的范围。$IQR = Q3 - Q1$
找出异常值
如何识别异常值:使用 IQR 识别异常值(outlier)
上界:$Q3 + 1.5 \cdot IQR$
下界:$Q1 - 1.5 \cdot IQR$
方差和标准差
方差(Variance):方差是平均差的均值。 计算方差的公式是:$$\sigma^2=\frac{\Sigma^{n}_{i=0}(x_i - \bar{x})^2}{n}$$
标准差(Standard Deviation):标准差是方差的平方根,用来衡量到均值的距离。
在正态分布中,$65\%$ 的数据与均值有 1 个标准偏差,2 个标准差内有 $95\%$,3 个标准差内有 $99.7\%$。
通常,抽样会低估了总体中差异性的数量,因为抽样往往是总体居于中间的值。特别是在正态分布中,多数值位于中间位置。因此我们从正态分布的总体中抽样时,多数值也在此处附近。因此样本的差异性将少于总体的差异性。
贝塞耳校正(Bessel’s Correction):校正对总体方差与标准差的预估。为了应用贝塞尔校正,我们用方差乘以 $\frac{n}{n - 1}$。
使用贝塞尔校正主要是为了估计总体标准差。
样本标准差
$$\mathrm s = \sqrt{\frac{\Sigma{(x_i - \bar {x})^2}}{n - 1}} \approx \sigma = \sqrt{\frac{\Sigma{(x_i - \bar {x})^2}}{n}}$$